
Large Language Models (LLMs) are incredibly powerful, possessing vast knowledge from their training data. However, they face a fundamental limitation: they can’t access or reason about your specific, private, or recent data. Even with today’s models supporting massive context windows of 100K+ tokens, organizations often need to work with datasets that are orders of magnitude larger.
Table of Contents
Quick Reference: Key Terms
- RAG: Retrieval-Augmented Generation - combining LLMs with the ability to search through your own data
- Embeddings: Numerical representations of text that capture meaning (think: words → numbers)
- Vector Database: Specialized storage for embeddings that enables semantic search
- Semantic Search: Finding information based on meaning rather than exact keyword matches
- Context Window: The amount of text an LLM can process at once
- Chunks: Smaller pieces of documents optimized for retrieval and processing
1. Why RAG?
Imagine you’re building an AI assistant that needs to answer questions about your company’s internal documentation, which spans thousands of documents and is updated daily. You have two options:
-
Fine-tuning the LLM: This means retraining the model on your data. While effective, it’s:
- Expensive and computationally intensive
- Time-consuming to implement
- Difficult to update (requires retraining for new information)
- Challenging to maintain version control
-
Using RAG: This approach dynamically fetches relevant information and feeds it to the LLM as context. It’s:
- More cost-effective
- Easy to update (just add new documents to your index)
- Maintains clear data lineage
- Flexible and scalable
2. How RAG Works: A Simple Example
Let’s say you’re building an AI assistant for a conference organization. Someone asks: “Who attended last year’s conference?”
Here’s how RAG handles this:
- Query Processing: The question is converted into a format that can be used to search your data
- Retrieval: The system searches a vector database containing your conference records
- Context Assembly: Relevant information (e.g., “The 2023 conference attendees were: Alice, Bob, Carol…”) is retrieved
- Generation: The LLM uses this specific context along with its general knowledge to formulate a natural response
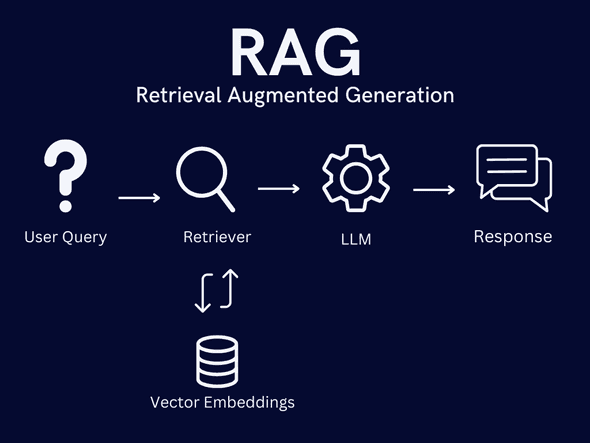
This simple flow masks sophisticated technology working behind the scenes. At its core, RAG depends on two key innovations:
- Vector Embeddings: A way to convert text into numerical representations that capture meaning
- Semantic Search: The ability to find information based on meaning rather than just keywords
3. The Building Blocks
To implement RAG, we need to:
-
Prepare Data: Convert our documents into a format that’s optimized for semantic search
- Break documents into appropriate chunks
- Convert text into vector embeddings
- Store in a vector database
-
Query System: Create a pipeline that can:
- Process user questions
- Find relevant information
- Combine context with LLM capabilities
- Generate accurate responses
In the following sections, we’ll dive deep into each of these components, understanding how they work and why they matter. While this article focuses on the theoretical foundations, Part 2 of this series will provide hands-on implementation using LangChain.js, showing you how to build these systems in practice.
But first, let’s understand the fundamental concept that makes RAG possible: vector embeddings and semantic space.
4. Introduction to Vector Space and Embeddings
Before diving into RAG implementation, it’s crucial to understand the fundamental concepts that make it possible. At the heart of modern RAG systems lies the concept of vector embeddings and semantic space.
4.1 Understanding Vector Space
Vector space is a mathematical construct where text is represented as high-dimensional vectors. When we talk about “embeddings,” we’re referring to the process of converting text into these vectors in a way that preserves semantic meaning. For example:
- The sentence “I love programming” might be converted into a vector like [0.2, -0.5, 0.8, …]
- A similar sentence “I enjoy coding” would have a similar vector representation
- An unrelated sentence would be represented by a very different vector
This is why vector similarity (often measured by cosine similarity) can capture semantic similarity - sentences with similar meanings end up close to each other in this high-dimensional space.
4.2 Embedding Models and Semantic Search
LangChain.js typically uses models like text-embedding-3-large, from OpenAI, which can convert text into 1536-dimensional vectors. These vectors capture nuanced semantic relationships:
- Synonyms cluster together in vector space
- Related concepts have smaller angular distances
- Antonyms tend to point in opposite directions
This mathematical representation enables “semantic search” - finding relevant information based on meaning rather than just keywords.
Cost Considerations for Embeddings
While LangChain supports various embedding models, be aware of cost implications:
- OpenAI’s text-embedding-3-large: Highest quality but most expensive (~$0.13/1M tokens)
- text-embedding-3-small: Good balance of quality and cost (~$0.02/1M tokens)
- Open-source alternatives (like Sentence Transformers): Free but require own infrastructure
For development and testing, consider using smaller models or caching embeddings to manage costs. Production systems should balance quality needs with budget constraints.
5. RAG Architecture Deep Dive
Now that we understand why RAG is useful and how vector embeddings work, let’s explore how LangChain helps us build these systems. LangChain provides a flexible framework for building RAG applications while abstracting away much of the complexity.
5.1 Document Processing with LangChain
LangChain provides built-in tools for handling documents through various loaders and text splitters:
Document Loading
LangChain supports multiple document types through its document loaders:
- PDF files (
PDFLoader) - Text files (
TextLoader) - CSV files (
CSVLoader) - Web pages (
WebBaseLoader) - And many more through community integrations
Instead of worrying about different file formats, you can focus on your data:
Key Benefits:
- Modular loader architecture
- Metadata preservation
- Built-in error handling
- Community-driven extensions
Text Chunking
LangChain offers several text splitting strategies:
-
Character Text Splitter
- Basic splitting by character count
- Good for simple text documents
-
Token Text Splitter
- Splits based on token count
- Ideal for managing LLM context windows
-
Recursive Character Text Splitter
- Intelligent splitting that respects document structure
- Recommended for most use cases
Quick tip:
- Use
RecursiveCharacterTextSplitteras your default choice- Set
chunk_sizearound 1000 for general use- Adjust
chunk_overlap(default 200) based on needs- Use
length_functionto customize token counting
5.2 Storage Options in LangChain
LangChain supports various vector stores:
Vector Store Options
-
In-Memory
HNSWLib: Fast local vector store- Good for development and small datasets
-
Persistent Storage
Chroma: Open-source, easy setupPinecone: Managed serviceWeaviate: Self-hosted or cloudFAISS: Meta’s vector store library
Choosing Storage
Development:
- Use
HNSWLibfor quick iteration Chromafor persistent local storage
Production:
Pineconefor managed scalingWeaviatefor self-hosted deployments
5.3 Retrieval in Practice
LangChain provides several retrieval methods:
Basic Options
-
Similarity Search
const results = await vectorStore.similaritySearch(query); -
MMR (Maximum Marginal Relevance)
const results = await vectorStore.maxMarginalRelevanceSearch(query);
Advanced Features
-
Hybrid Search
- Combines keyword and semantic search
- Available through
HybrideRetriever
-
Self-Query Retrieval
- Lets LLM interpret and modify queries
- Supports metadata filtering
5.4 Chain Composition
LangChain excels at composing retrieval and generation chains:
Basic RAG Chain
const chain = RunnableSequence.from([
{
context: retriever.pipe(formatDocumentsAsString),
question: new RunnablePassthrough(),
},
prompt,
model,
new StringOutputParser(),
]);Advanced Features
-
Conversation Memory
- Add chat history to context
- Maintain conversation state
-
Streaming Responses
- Stream tokens as they’re generated
- Provide real-time feedback
[Rest of the article remains similar, with LangChain-specific examples where relevant]
6. Looking Ahead: Advanced Features
While LangChain handles the basics well, it also supports advanced use cases:
Multi-Modal Support
Beyond Text:
- Image processing (coming soon)
- PDF with images
- Structured data
Integration Options
Extend functionality:
- Custom embedding models
- Different LLM providers
- External tools and services
These concepts form the foundation for Part 2 of our series, where we’ll implement these features using LangChain.js code. Understanding these components helps us make better choices in our implementations, even though LangChain handles much of the complexity for us.
7. Conclusion: Building Effective RAG Systems
We’ve covered the fundamental concepts and architecture of RAG systems, focusing on how LangChain makes implementation accessible while maintaining flexibility for advanced use cases. Key takeaways include:
-
RAG’s Advantage:
- Provides a practical alternative to fine-tuning
- Enables dynamic access to your data
- Offers cost-effective scaling
-
Core Components:
- Vector embeddings for semantic understanding
- Efficient document processing and storage
- Smart retrieval and context management
-
Implementation Considerations:
- Choose appropriate chunking strategies
- Select storage based on scale requirements
- Configure retrieval methods for your use case
In Part 2 of this series, we’ll translate these concepts into practice, building a complete RAG system with LangChain.js. I’ll show you how to:
- Set up document processing
- Configure vector storage
- Implement retrieval strategies
- Optimize system performance
Stay tuned for hands-on implementation examples and practical tips for building production-ready RAG applications.




