
In Part 2, we built a functional RAG system using LangChain to answer questions about Wikipedia articles. Now, let’s enhance our implementation with advanced features, better retrieval, and production-ready optimizations.
Table of Contents
1. System Architecture Overview
Our enhanced RAG system builds on Part 2’s foundation with three major improvements:
- Hybrid Retrieval: Combines vector and keyword search for better accuracy
- Streaming Responses: Provides real-time feedback for long responses
- Production Optimizations: Adds caching, monitoring, and error handling
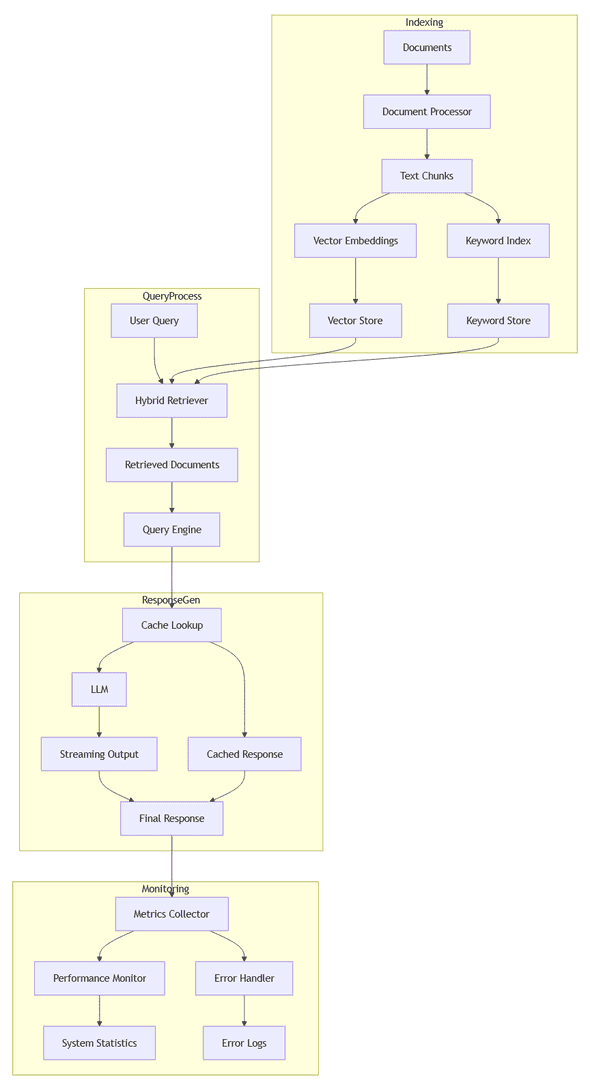
Your project structure will look like this:
Your project structure should look like this:
```text
rag-tutorial/
├── lib/
│ ├── hybrid-retriever.js # Enhanced retrieval
│ ├── enhanced-query.js # Query processing
│ ├── cache.js # Response caching
│ ├── metrics.js # Performance monitoring
│ └── optimized-engine.js # Production engine
├── scripts/
│ └── test-enhanced-rag.js # Testing script
└── package.json2. Enhancing Retrieval Quality
Let’s start by improving how our system finds relevant information. Our Part 2 implementation used basic vector similarity search, but we can do better.
2.1 Hybrid Search Implementation
Vector search, while powerful for semantic understanding, has limitations. When you search “Who won the 2024 election?”, a pure vector search might miss documents containing “victory” or “defeat” if those exact terms weren’t part of the training data. Additionally, vector search can sometimes miss exact phrase matches that would be obvious to humans.
Hybrid search addresses these limitations by combining two approaches:
-
Vector (Semantic) Search:
- Uses embeddings to understand meaning
- Great for conceptual matching
- Handles paraphrasing and synonyms
- Can miss exact matches
-
Keyword (Lexical) Search:
- Uses traditional text matching (TF-IDF)
- Excellent for exact matches
- Handles specific terms and phrases
- Misses semantic relationships
By combining both vector and keyword search, we get the best of both worlds: semantic understanding and precise matching. While the Python version of LangChain includes TF-IDF (Term Frequency-Inverse Document Frequency) for sophisticated keyword matching, in JavaScript we’ll implement a simpler but effective text matching approach. This demonstrates the core concepts while remaining practical for production use.
Our implementation focuses on:
- Parallel execution of both search types
- Smart result combination
- Configurable weighting
- Clean interface integration
Create lib/hybrid-retriever.js:
import { MemoryVectorStore } from "langchain/vectorstores/memory";
export class HybridRetriever {
constructor(documents, embeddings, options = {}) {
this.vectorStore = new MemoryVectorStore(embeddings);
this.documents = documents;
this.options = {
vectorWeight: options.vectorWeight || 0.7,
keywordWeight: options.keywordWeight || 0.3,
minScore: options.minScore || 0.3
};
}
static async fromDocuments(documents, embeddings) {
const hybrid = new HybridRetriever(documents, embeddings);
await hybrid.vectorStore.addDocuments(documents);
return hybrid;
}
// Simple keyword search
keywordSearch(query, documents, k = 2) {
const queryTerms = query.toLowerCase().split(' ');
// Score documents based on term matches
const scoredDocs = documents.map(doc => {
const content = doc.pageContent.toLowerCase();
const score = queryTerms.reduce((acc, term) => {
// Count exact matches
const exactMatches = (content.match(new RegExp(term, 'g')) || []).length;
return acc + exactMatches;
}, 0);
return { document: doc, score };
});
// Return top k results
return scoredDocs
.filter(doc => doc.score > 0)
.sort((a, b) => b.score - a.score)
.slice(0, k)
.map(doc => ({
...doc.document,
metadata: { ...doc.document.metadata, score: 0.8, source: 'keyword' }
}));
}
async getRelevantDocuments(query, options = { vectorK: 3, keywordK: 2 }) {
// Get results from both methods
const [vectorDocs, keywordDocs] = await Promise.all([
this.vectorStore.similaritySearch(query, options.vectorK),
Promise.resolve(this.keywordSearch(query, this.documents, options.keywordK))
]);
// Combine results, prioritizing vector search
const seenContents = new Set();
const combined = [];
// Add vector results first
for (const doc of vectorDocs) {
if (!seenContents.has(doc.pageContent)) {
seenContents.add(doc.pageContent);
combined.push({
...doc,
metadata: { ...doc.metadata, score: 1.0, source: 'vector' }
});
}
}
// Add keyword results
for (const doc of keywordDocs) {
if (!seenContents.has(doc.pageContent)) {
seenContents.add(doc.pageContent);
combined.push(doc);
}
}
return combined;
}
}2.2 Enhanced Query Engine
The Enhanced Query Engine implementation builds on this hybrid retriever to create a more sophisticated query processing pipeline.
Update our query engine to use hybrid search. Create lib/enhanced-query.js:
import { ChatOpenAI } from "@langchain/openai";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { RunnableSequence } from "@langchain/core/runnables";
import { OpenAIEmbeddings } from "@langchain/openai";
import { PromptTemplate } from "@langchain/core/prompts";
import { HybridRetriever } from './hybrid-retriever.js';
const ENHANCED_PROMPT = `You are analyzing Wikipedia content to provide accurate information. The context comes from both vector (semantic) and keyword searches.
Context information (ranked by relevance):
-----------------------------------------
{context}
-----------------------------------------
Please provide a detailed answer that:
1. Directly answers the question
2. Notes dates and timeline information
3. References which search method found the information
4. Expresses uncertainty for very recent events
Question: {question}
Detailed answer:`;
async function formatDocuments(docs) {
return docs.map((doc, i) => {
const source = doc.metadata?.source || 'unknown';
const score = doc.metadata?.score || 'N/A';
return `[${i + 1}] (${source} search, score: ${score})\n${doc.pageContent}\n`;
}).join('\n');
}
export async function createEnhancedQueryEngine(documents) {
const embeddings = new OpenAIEmbeddings();
const retriever = await HybridRetriever.fromDocuments(documents, embeddings);
const model = new ChatOpenAI({
modelName: 'gpt-3.5-turbo',
temperature: 0.3,
});
const prompt = PromptTemplate.fromTemplate(ENHANCED_PROMPT);
const chain = RunnableSequence.from([
{
// This properly formats the input for the prompt
context: async (input) => {
const docs = await retriever.getRelevantDocuments(input.question);
return formatDocuments(docs);
},
question: (input) => input.question,
},
// The prompt template converts the input into a prompt
prompt,
// The model processes the prompt
model,
// The output parser converts the model output to a string
new StringOutputParser()
]);
return chain;
}2.3 Testing the Enhanced Query Engine
Create a new file scripts/test-hybrid.js:
import { loadDocuments } from '../lib/document-loader.js';
import { createEnhancedQueryEngine } from '../lib/enhanced-query.js';
async function testHybridQueries() {
console.log('Loading documents...');
const documents = await loadDocuments();
console.log('Initializing enhanced query engine...');
const queryEngine = await createEnhancedQueryEngine(documents);
const questions = [
"What are Donald Trump's most recent political activities?",
"What legal challenges is Trump currently facing?",
"Who won and who was the runner up in the 2024 Republican primaries?"
];
console.log('\nTesting enhanced retrieval with sample queries...\n');
for (const question of questions) {
console.log(`Question: ${question}`);
console.log('Processing...');
const startTime = performance.now();
const response = await queryEngine.invoke({ question });
const duration = performance.now() - startTime;
console.log('\nAnswer:', response);
console.log(`Duration: ${Math.round(duration)}ms\n`);
console.log('-'.repeat(50), '\n');
}
}
testHybridQueries().catch(console.error);Run the script with node scripts/test-hybrid.js.
Output:
Loading documents...
Split into 165 chunks
Initializing enhanced query engine...
Testing enhanced retrieval with sample queries...
Question: What are Donald Trump's most recent political activities?
Processing...
Answer: Donald Trump's most recent political activities include his continued dominance within the Republican Party, where he has been described as a modern party boss. He has focused on fundraising, raising more than twice as much as the Republican Party itself, and profiting from fundraisers held at Mar-a-Lago. Trump has also been actively involved in endorsing over 200 candidates for various offices in the 2022 midterm elections, most of whom supported his false claim that the 2020 presidential election was stolen from him. Additionally, he has been focused on how elections are run and has been involved in efforts to oust election officials who resisted his attempts to overturn the 2020 election results.
Duration: 2540ms
--------------------------------------------------
Question: What legal challenges is Trump currently facing?
Processing...
Answer: As of September 2023, Donald Trump is facing multiple legal challenges. In September 2022, the attorney general of New York filed a civil fraud case against Trump, his three oldest children, and the Trump Organization. Trump was fined $110,000 for failing to turn over records subpoenaed by the attorney general. In February 2024, the court found Trump liable, ordering him to pay a penalty of more than $350 million plus interest, totaling over $450 million. Additionally, Trump was barred from serving as an officer or director of any New York corporation or legal entity for three years. Trump has stated his intention to appeal the verdict. Furthermore, Trump was sued for violating the Domestic and Foreign Emoluments Clauses of the U.S. Constitution, with cases being dismissed by the U.S. Supreme Court as moot after the end of his term.
Duration: 2811ms
--------------------------------------------------
Question: Who won and who was the runner up in the 2024 general election?
Processing...
Answer: In the 2024 general election, Donald Trump was elected as the 47th president of the United States, defeating incumbent vice president Kamala Harris. Trump won with 49.9% of the vote and a margin of 1.6% over his opponent, making him the first Republican to win the popular vote since 2004. Kamala Harris was the runner-up in the election. The Associated Press and BBC News described Trump's victory as an extraordinary comeback for a former president.
Duration: 2134ms
-------------------------------------------------- Analyzing Our Results
Let’s examine how well our hybrid retrieval system performed:
- Recent Political Activities Query:
What are Donald Trump's most recent political activities?The response focuses on older events (2022 midterms and fundraising) but misses the most significant recent developments: his 2024 presidential campaign, victory, and upcoming inauguration. This shows a limitation in our system where recency isn’t properly prioritized in the retrieval process.
- Legal Challenges Query:
What legal challenges is Trump currently facing?While it provides good detail about the New York civil fraud case, it misses several major legal challenges including his criminal conviction, the Georgia case, and the E. Jean Carroll verdicts. This suggests our retrieval system isn’t effectively gathering information spread across multiple chunks.
- 2024 Election Query:
Who won and who was the runner up in the 2024 general election?This response is the most accurate and complete, correctly identifying Trump’s victory over Kamala Harris and including specific vote percentages. It works well because the information is likely contained in a single, well-defined chunk of text.
These results show that while hybrid retrieval can be effective, it still faces challenges with:
- Prioritizing recent information
- Gathering comprehensive information spread across multiple chunks
- Consistently finding the most relevant content
Key differences from Part 2’s implementation:
- Hybrid Retrieval: Combines both vector and keyword search results
- Source Attribution: The prompt and formatting show which retrieval method found each piece of information
- Scoring: Documents are scored based on their retrieval method and relevance
- Enhanced Context: The prompt template is designed to make better use of the dual retrieval sources
The hybrid approach should provide more comprehensive results, especially for:
- Questions with specific names or dates
- Queries that combine conceptual and factual elements
- Recent events that might be described with varying terminology
3. Production Optimizations
Let’s explore two key optimizations that make our RAG system production-ready: streaming responses and basic caching.
3.1 Streaming Responses
Long responses can take several seconds to generate, leading to poor user experience. Streaming solves this by sending chunks of the response as they’re generated. This provides immediate feedback and better user engagement.
Update lib/enhanced-query.js to support streaming:
import { ChatOpenAI } from "@langchain/openai";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { RunnableSequence } from "@langchain/core/runnables";
export async function createStreamingQueryEngine(documents) {
const retriever = await HybridRetriever.fromDocuments(documents, embeddings);
const model = new ChatOpenAI({
modelName: 'gpt-3.5-turbo',
temperature: 0.1,
streaming: true
});
const chain = RunnableSequence.from([
{
context: async (input) => {
const docs = await retriever.getRelevantDocuments(input.question);
return formatDocuments(docs);
},
question: (input) => input.question,
},
prompt,
model,
new StringOutputParser()
]);
return chain;
}The streaming implementation will be fully utilized in Part 4’s web interface. For now, we can test it with a simple script:
import { createStreamingQueryEngine } from '../lib/enhanced-query.js';
async function testStreaming() {
const engine = await createStreamingQueryEngine(documents);
const stream = await engine.stream({
question: "What are Trump's current legal challenges?"
});
for await (const chunk of stream) {
process.stdout.write(chunk);
}
}3.2 Basic Response Caching
Implementing a simple cache can significantly improve response times for repeated queries. Here’s a straightforward caching implementation using LRU (Least Recently Used) strategy:
import { LRUCache } from 'lru-cache';
export class SimpleCache {
constructor(options = {}) {
this.cache = new LRUCache({
max: options.maxSize || 100,
ttl: options.ttl || 1000 * 60 * 60 // 1 hour default
});
}
async get(query) {
return this.cache.get(query);
}
async set(query, response) {
this.cache.set(query, response);
}
}Integration with our query engine:
export class CachedQueryEngine {
constructor(documents) {
this.cache = new SimpleCache();
this.queryEngine = createEnhancedQueryEngine(documents);
}
async query(question, options = {}) {
// Skip cache for streaming requests
if (options.stream) {
return this.queryEngine.stream({ question });
}
const cachedResponse = await this.cache.get(question);
if (cachedResponse) {
return cachedResponse;
}
const response = await this.queryEngine.invoke({ question });
await this.cache.set(question, response);
return response;
}
}4. Best Practices and Common Challenges
Based on our implementation experience, here are key considerations for production RAG systems:
4.1 Error Handling
Common error scenarios to handle:
- API rate limits
- Token context length exceeded
- Network timeouts
- Invalid or missing documents
Example error handling implementation:
async function queryWithRetry(question, maxRetries = 3) {
for (let i = 0; i < maxRetries; i++) {
try {
return await queryEngine.query(question);
} catch (error) {
if (error.message.includes('rate limit') && i < maxRetries - 1) {
await new Promise(r => setTimeout(r, Math.pow(2, i) * 1000));
continue;
}
throw error;
}
}
}4.2 Performance Considerations
Key areas to monitor and optimize:
-
Document Retrieval
- Tune chunk sizes (1000 tokens works well)
- Adjust vector vs keyword result ratios
- Monitor retrieval times
-
Response Generation
- Use streaming for long responses
- Implement basic caching
- Set appropriate timeouts
-
Resource Usage
- Monitor memory usage for vector storage
- Track API token consumption
- Cache hit rates
5. Next Steps
In Part 4, we’ll build a complete web interface for our RAG system, including:
- Real-time streaming display
- Source attribution
- Error handling
- Performance monitoring
The interface will demonstrate how to effectively use the streaming and caching capabilities we’ve implemented here.
Conclusion
Our enhanced RAG system now provides better search accuracy through hybrid retrieval, improved user experience with streaming, and better performance through caching. While there’s always room for more sophisticated optimizations, this implementation provides a solid foundation for production use.




