
In Part 1, we explored the theoretical foundations of RAG systems. Now, let’s build a working implementation! We’ll create a RAG system that answers questions about recent Wikipedia articles, showing how LLMs can work with fresh data.
Table of Contents
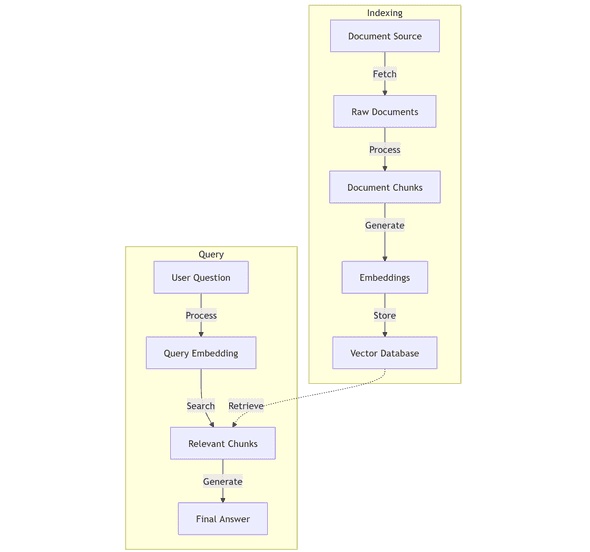
1. System Architecture
A RAG system operates in two distinct phases: indexing and querying. Understanding these phases is crucial for both development and production deployment.
1. Indexing Phase
The indexing phase prepares your documents for efficient retrieval. During this phase, the system:
- Fetches and processes documents from your data sources
- Splits them into optimal chunks for context retention
- Generates vector embeddings for semantic understanding
- Stores them in a vector database for quick access
In production environments, this phase typically runs as a background process. You might schedule it to run on a fixed schedule or trigger it when source documents update. This ensures your knowledge base remains current without impacting real-time query performance.
2. Query Phase
The query phase handles real-time user interactions. When a query comes in:
- The system processes the user’s question
- Retrieves the most semantically relevant chunks
- Uses an LLM to generate a coherent response
This process happens in real-time as part of your application’s request-response cycle, typically completing within seconds.
2. Building the Indexing Pipeline
2.1 Project Setup
We’ll use Next.js as our application framework and LangChain as our RAG toolkit. This combination provides a robust foundation for building production-ready RAG systems.
npx create-next-app@latest rag-tutorial --javascript --tailwind --eslint
cd rag-tutorial
npm install @langchain/openai @langchain/community langchainEnvironment Setup
Proper environment configuration is essential for development and production environments. We need to manage API keys and other sensitive configuration securely.
npm install dotenvCreate your environment files:
# .env (for development)
OPENAI_API_KEY=your_api_key_here
# .env.local (for Next.js)
OPENAI_API_KEY=your_api_key_hereImportant: These files contain sensitive credentials. Add them to your
.gitignoreto prevent accidental commits.
For scripts outside Next.js, import the environment configuration:
import 'dotenv/config';2.2 Getting Our Data
We’re using Wikipedia as our data source for several practical reasons:
- The API provides clean, structured content
- Articles are regularly updated
- Content is well-formatted and requires minimal preprocessing
- Perfect for demonstrating how RAG handles current events
Let’s create a simple script to fetch and prepare data from Wikipedia. This is a great example of how RAG systems can work with current information that exists outside of the LLM’s training cutoff date. Create a new file scripts/fetch-articles.js:
import { writeFileSync } from 'fs';
async function fetchArticles() {
// Wikipedia API endpoint for full article content
const url = 'https://en.wikipedia.org/w/api.php?action=query&format=json&prop=extracts&titles=Donald_Trump&explaintext=1&origin=*';
try {
const response = await fetch(url);
const data = await response.json();
// Extract the page content (need to get the first page from pages object)
const pageId = Object.keys(data.query.pages)[0];
const article = {
title: data.query.pages[pageId].title,
content: data.query.pages[pageId].extract
};
// Save to file
writeFileSync(
'./data/article-1.txt',
`${article.title}\n\n${article.content}`
);
console.log('Article saved successfully');
} catch (error) {
console.error('Error fetching article:', error);
}
}
fetchArticles();Create a data directory and run the script:
mkdir data
node scripts/fetch-articles.jsOutput:
Article saved successfullyImportant: Since we’re using ES modules outside of Next.js, add
"type": "module"to your package.json file:{ "name": "rag-tutorial", "type": "module", ... }
Why Wikipedia?
While we could fetch data from various news sources, Wikipedia offers several advantages for this tutorial:
- Reliable API: Wikipedia provides a stable, well-documented API that’s easy to work with
- Structured Data: The content is already well-formatted and cleaned
- Current Events: Wikipedia pages are regularly updated with recent information
- Educational Purpose: Using Donald Trump’s page as an example helps demonstrate how RAG systems can provide information about recent events that occurred after the LLM’s training cutoff date
2.3 Document Processing
The document processing step is critical for retrieval quality. We implement intelligent chunking that:
- Maintains semantic coherence with 1000-token chunks
- Preserves context through 200-token overlaps
- Retains metadata for traceability
- Uses natural break points like paragraphs
First, let’s create a robust document loader that handles chunking and metadata. Create lib/document-loader.js:
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import * as fs from 'fs';
export async function loadDocuments() {
const text = fs.readFileSync('./data/article-1.txt', 'utf8');
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
separators: ['\n\n', '\n', '. ', ' ', '']
});
const documents = await splitter.createDocuments(
[text],
[{
source: 'wikipedia',
date: new Date().toISOString(),
type: 'article'
}]
);
console.log(`Split into ${documents.length} chunks`);
return documents;
}
export function analyzeChunks(documents) {
return documents.map((doc, index) => ({
chunkIndex: index,
length: doc.pageContent.length,
completeSentences: doc.pageContent.split('. ').length,
text: doc.pageContent,
metadata: doc.metadata
}));
}Chunk Quality Note: Analyzing your chunks helps identify potential issues like:
- Chunks that are too short or too long
- Chunks with incomplete sentences
- Uneven chunk distribution
Poor chunking can lead to lower quality responses, so it’s worth monitoring during development.
Let’s analyze our chunks. Create scripts/analyze-chunks.js:
import { loadDocuments, analyzeChunks } from '../lib/document-loader.js';
async function analyzeDocument() {
const documents = await loadDocuments();
const analysis = analyzeChunks(documents);
console.log(`\nDocument Analysis Results:`);
console.log(`Total chunks: ${documents.length}`);
// Add some statistics
const avgLength = Math.round(
analysis.reduce((sum, chunk) => sum + chunk.length, 0) / analysis.length
);
const avgSentences = Math.round(
analysis.reduce((sum, chunk) => sum + chunk.completeSentences, 0) / analysis.length
);
console.log(`\nStatistics:`);
console.log(`- Average chunk length: ${avgLength} characters`);
console.log(`- Average sentences per chunk: ${avgSentences}`);
console.log('\nSample chunks:');
analysis.slice(0, 3).forEach(chunk => {
console.log(`\nChunk ${chunk.chunkIndex}:`);
console.log(`- Length: ${chunk.length} characters`);
console.log(`- Sentences: ${chunk.completeSentences}`);
console.log(`- Preview: "${chunk.text?.substring(0, 100)}..."`);
console.log('---');
});
}
analyzeDocument().catch(console.error);Run the analysis:
node scripts/analyze-chunks.jsExample output:
Split into 165 chunks
Document Analysis Results:
Total chunks: 165
Statistics:
- Average chunk length: 624 characters
- Average sentences per chunk: 5
Sample chunks:
Chunk 0:
- Length: 12 characters
- Sentences: 1
- Preview: "Donald Trump..."
---
Chunk 1:
- Length: 774 characters
- Sentences: 6
- Preview: "Donald John Trump (born June 14, 1946) is an American politician, media personality, and businessman..."
---
Chunk 2:
- Length: 871 characters
- Sentences: 9
- Preview: "presidential campaign.
Trump won the 2016 presidential election. His election and policies sparked n..."
---2.4 Vector Store Management
The vector store serves as our primary retrieval mechanism. It:
- Stores document embeddings efficiently
- Enables semantic similarity search
- Persists data between application restarts
- Supports incremental updates
Create lib/storage.js to handle vector store operations:
import { OpenAIEmbeddings } from "@langchain/openai";
import { HNSWLib } from "@langchain/community/vectorstores/hnswlib";
let vectorStore = null;
export async function setupVectorStore(documents) {
if (vectorStore) return vectorStore;
const embeddings = new OpenAIEmbeddings();
// HNSWLib parameters explanation:
// - Space: 'cosine' for cosine similarity
// - numDimensions: 1536 for OpenAI embeddings
vectorStore = await HNSWLib.fromDocuments(documents, embeddings);
return vectorStore;
}
export async function saveVectorStore(directory = "./data") {
if (!vectorStore) throw new Error("Vector store not initialized");
await vectorStore.save(directory);
}
export async function loadVectorStore(directory = "./data") {
const embeddings = new OpenAIEmbeddings();
vectorStore = await HNSWLib.load(directory, embeddings);
return vectorStore;
}
// Helper function to manage vector store lifecycle
export async function getOrCreateVectorStore(documents) {
try {
// Try to load existing vector store
return await loadVectorStore();
} catch (error) {
// Create new vector store if loading fails
console.log("Creating new vector store...");
const store = await setupVectorStore(documents);
await saveVectorStore();
return store;
}
}Create a script to build our index, scripts/build-index.js:
import { loadDocuments } from '../lib/document-loader.js';
import { setupVectorStore } from '../lib/storage.js';
async function buildIndex() {
console.log('Loading documents...');
const documents = await loadDocuments();
console.log('Building vector store...');
await setupVectorStore(documents);
console.log('Index built successfully!');
}
buildIndex().catch(console.error);Run it:
node scripts/build-index.jsOutput:
Loading documents...
Split into 165 chunks
Building vector store...
Index built successfully!3. Building the Query Pipeline
3.1 Query Engine
The query engine coordinates the retrieval and response generation process. It:
- Manages the retrieval chain
- Handles prompt templates
- Orchestrates the LLM interaction
- Formats the final response
Create lib/prompts.js for our prompt templates:
import { PromptTemplate } from "@langchain/core/prompts";
export const PROMPT_TEMPLATES = {
default: `Answer the question based only on the following context:
{context}
Question: {question}
Answer:`,
detailed: `You are analyzing Wikipedia content to provide accurate information.
Context information:
-------------------
{context}
-------------------
Please provide a detailed answer that:
1. Directly answers the question
2. Notes dates and timeline information
3. Expresses uncertainty when appropriate
4. Mentions if events are recent/ongoing
Question: {question}
Detailed answer:`,
};
export function createPrompt(type = 'default') {
return PromptTemplate.fromTemplate(PROMPT_TEMPLATES[type]);
}Create lib/query-engine.js:
import { ChatOpenAI } from "@langchain/openai";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { RunnableSequence, RunnablePassthrough } from "@langchain/core/runnables";
import { formatDocumentsAsString } from "langchain/util/document";
import { createPrompt } from './prompts';
import { loadDocuments } from './document-loader';
import { getOrCreateVectorStore } from './storage';
let chain = null;
export async function initializeChain(promptType = 'default') {
if (chain) return chain;
const documents = await loadDocuments();
const vectorStore = await getOrCreateVectorStore(documents);
const retriever = vectorStore.asRetriever();
// Temperature of 0.7 balances creativity and accuracy:
// - 0.0: Most deterministic, best for fact retrieval
// - 0.7: Good balance for natural responses while maintaining accuracy
// - 1.0: Maximum creativity, may diverge from context
const model = new ChatOpenAI({
modelName: 'gpt-3.5-turbo',
temperature: 0.7,
});
const prompt = createPrompt(promptType);
chain = RunnableSequence.from([
{
context: retriever.pipe(formatDocumentsAsString),
question: new RunnablePassthrough(),
},
prompt,
model,
new StringOutputParser(),
]);
return chain;
}
export async function queryDocuments(question, options = {}) {
const queryChain = await initializeChain(options.promptType);
try {
const response = await queryChain.invoke(question);
return {
answer: response,
metadata: {
promptType: options.promptType || 'default',
timestamp: new Date().toISOString()
}
};
} catch (error) {
console.error('Query failed:', error);
// Handle specific error cases
if (error.message.includes('rate limit')) {
throw new Error('Rate limit exceeded. Please try again later.');
}
if (error.message.includes('maximum context length')) {
throw new Error('Question too complex. Please try a simpler query.');
}
throw error;
}
}3.2 Testing the System
Create scripts/test-queries.js:
import { queryDocuments } from '../lib/query-engine.js';
async function testQueries() {
const questions = [
"What are Donald Trump's most recent political activities?",
"What legal challenges is Trump currently facing?",
"Who won and who as the runner up in the 2024 Republican primaries?"
];
console.log('Testing RAG system with sample queries...\n');
for (const question of questions) {
console.log(`Question: ${question}`);
console.log('Thinking...');
const startTime = Date.now();
const answer = await queryDocuments(question);
const duration = Date.now() - startTime;
console.log('\nAnswer:', answer);
console.log(`Duration: ${duration}ms\n`);
console.log('-'.repeat(50), '\n');
}
}
testQueries().catch(console.error);Run the tests:
node scripts/test-queries.jsExample output:
Testing RAG system with sample queries...
Question: What are Donald Trump's most recent political activities?
Thinking...
Split into 165 chunks
Answer: {
answer: 'In the 2022 midterm elections, Donald Trump endorsed over 200 candidates for various offices, most of whom supported his false claim that the 2020 presidential election was stolen from him. He continued fundraising, raised more than twice as much as the Republican Party itself, and focused on how elections are run and on ousting election officials who had resisted his attempts to overturn the 2020 election results.',
metadata: { promptType: 'default', timestamp: '2024-11-25T21:12:02.827Z' }
}
Duration: 2170ms
--------------------------------------------------
Question: What legal challenges is Trump currently facing?
Thinking...
Answer: {
answer: 'Trump is currently facing a civil fraud case filed by the attorney general of New York, in which he was found liable, ordered to pay a penalty of over $450 million, and barred from serving as an officer or director of any New York corporation or legal entity for three years. Additionally, he is facing federal charges related to national defense information under the Espionage Act, making false statements, conspiracy to obstruct justice, and other charges.',
metadata: { promptType: 'default', timestamp: '2024-11-25T21:12:04.824Z' }
}
Duration: 1995ms
--------------------------------------------------
Question: Who won and who as the runner up in the 2024 Republican primaries?
Thinking...
Answer: {
answer: 'Donald Trump won the 2024 Republican primaries and Kamala Harris was the runner up.',
metadata: { promptType: 'default', timestamp: '2024-11-25T21:12:05.914Z' }
}
Duration: 1090ms
-------------------------------------------------- 4. Best Practices and Optimization
Based on our implementation, here are key practices we’ve followed:
-
Chunk Size Optimization
- We used 1000-token chunks with 200-token overlap
- This balanced context retention with processing efficiency
- Larger chunks would provide more context but increase API costs
- Smaller chunks might miss important relationships
-
Prompt Engineering
- Our prompt template explicitly bounds the context
- We instruct the model to acknowledge when information might be too recent
- The temperature of 0.7 balances accuracy with natural responses
-
Error Handling
- Each component has proper error handling
- The system gracefully handles missing or invalid data
- API rate limits and timeouts are considered
5. Common Issues and Solutions
When implementing this RAG system, you might encounter these common challenges:
1. OpenAI API Rate Limits
Error: Rate limit exceeded. Please try again later.Solution: Implement exponential backoff or use token bucket rate limiting:
const wait = (ms) => new Promise(resolve => setTimeout(resolve, ms));
const queryWithRetry = async (question, retries = 3) => {
for (let i = 0; i < retries; i++) {
try {
return await queryDocuments(question);
} catch (error) {
if (error.message.includes('rate limit') && i < retries - 1) {
await wait(Math.pow(2, i) * 1000);
continue;
}
throw error;
}
}
};2. Vector Store Persistence
If you see Error: Vector store not initialized, check:
- Directory permissions
- File corruption in the
./datadirectory - Sufficient disk space
3. Large Documents
For maximum context length errors:
- Reduce chunk size (try 500 tokens)
- Decrease chunk overlap
- Use more selective retrieval
4. Memory Issues
If processing large articles:
- Process documents in batches
- Implement streaming for large files
- Monitor memory usage during embedding generation
6. What’s Next in the Series?
This tutorial got you started with a working RAG system that can process Wikipedia articles and answer questions about them. In the upcoming parts of this series, we’ll expand this foundation:
Part 3: Advanced RAG Features
- Hybrid search implementations
- Response streaming
- Advanced caching strategies
- Multi-document querying
- Cost optimization techniques
Part 4: Building the Web Interface
- Creating the Next.js API endpoint we prepared
- Implementing real-time streaming responses
- Building an interactive UI with:
- Query input
- Response streaming display
- Source attribution
- Confidence scoring
- Adding proper error handling and loading states
Try It Now
While waiting for the next parts, you can experiment with this implementation:
- Try different chunk sizes and overlap settings
- Test with other Wikipedia articles
- Modify the prompt templates
- Add more error handling cases




