
In the world of AI and large language models (LLMs), there’s often a trade-off between power and practicality. While models like GPT-4 offer impressive capabilities, they require cloud access and can be expensive for development and testing. This is where Ollama comes in - a tool that lets you run powerful language models locally on your own machine.
Table of Contents
1. Getting Started
1.1 Why Ollama?
Before diving into the technical details, let’s understand why you might want to use Ollama:
- Development Freedom: Run AI models locally without internet dependency
- Cost Effective: No API costs or usage limits
- Privacy: Your data stays on your machine
- Perfect for Testing: Ideal for development and prototyping
- Resource Friendly: Can run on consumer hardware (even MacBooks!)
1.2 Prerequisites
- Hardware Requirements:
- Minimum: 8GB RAM (limited to smaller models)
- Recommended: 16GB+ RAM
- Disk Space: ~4GB per model downloaded
- Basic familiarity with terminal/command line
- Node.js installed (for API examples)
1.3 Installation
Setting up Ollama is straightforward. For Mac and Linux users:
curl https://ollama.ai/install.sh | shFor Windows users, download the installer from ollama.ai.
After installation, you can start using Ollama immediately:
ollama run llama3.1:8bThis downloads and runs an 8-billion parameter model - a good starting point for most use cases.
2. Understanding Ollama
2.1 Model Sizes and Capabilities
One key advantage of Ollama is its flexibility with model sizes. While cloud models like GPT-4 (>400 billion parameters) are powerful, Ollama shines with smaller, more efficient models:
- 8-9B Parameter Models: These provide a perfect balance of capability and resource usage. Think of them as compact but powerful engines - they might not write a novel, but they excel at practical tasks.
2.2 Quantization Options
These are different ways to compress the model while maintaining performance:
- Q4_0: The “goldilocks” option - good balance of speed and accuracy
- Q2_K: When you need lightning-fast responses
- F16: When precision is crucial
Let’s see this in action:
# Compare speed between different quantization levels
time ollama run llama3.1:8b-text-q4_0 "Describe a black hole in one paragraph"
time ollama run llama3.1:8b-text-q2_K "Describe a black hole in one paragraph"I can see that the q2_K model struggles a lot more to understand questions and give correct answers, I actually got it into a loop where it was answering non stop as you can see below:
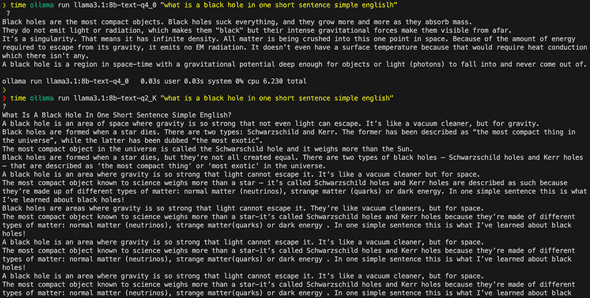
2.3 Basic Commands
Here are some commands you’ll use often:
ollama run # Use a model
ollama pull # Download a model
ollama list # See your models
ollama rm # Delete a model
ollama cp # Copy a model
ollama create # Make a new model
ollama --help # More info3. Basic Usage
3.1 Managing Models
Check your installed models:
ollama listIn my case I have installed:
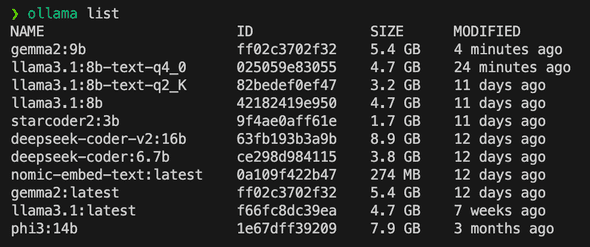
Download a new model:
ollama pull llama3.1:8b3.2 Simple Interactions
Try basic tasks:
ollama run llama3.1:8b "Write a funny short poem about programming"
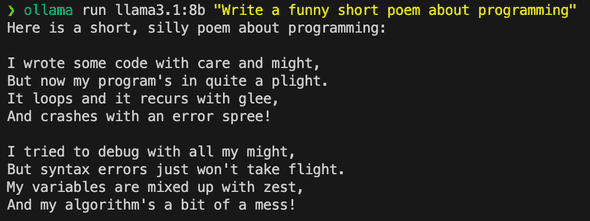
Compare different models:
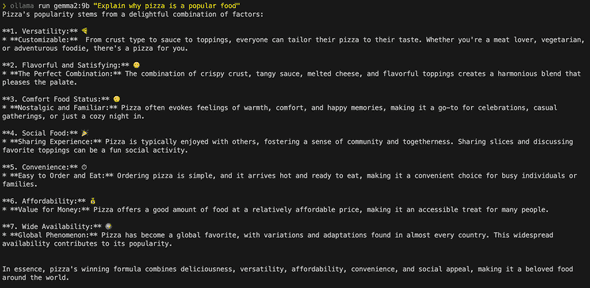
ollama run llama3.1:8b "Explain why pizza is a popular food"
ollama run gemma2:9b "Explain why pizza is a popular food"See the results below:
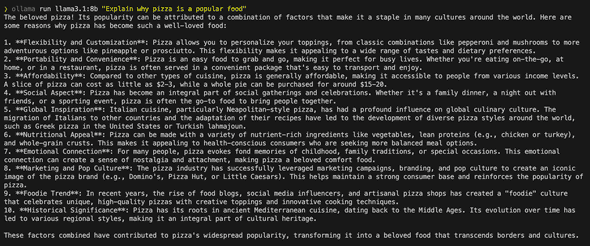
4. Working with the API
4.1 API Overview
While running LLMs through the command line is great, Ollama’s real power comes from its HTTP API. Here’s how you can integrate local LLMs into your applications:
All API calls are made to localhost:11434. This means:
- No authentication required
- No rate limiting
- Typical response times: <100ms
- Works completely offline
4.2 Core Endpoints
4.2.1 Generate Completions
async function generateText(prompt) {
const response = await fetch('http://localhost:11434/api/generate', {
method: 'POST',
body: JSON.stringify({
model: 'llama3.1:8b',
prompt,
stream: false // Get full response instead of streaming
})
});
return response.json();
}
// Example usage
const result = await generateText('Explain quantum computing');
console.log(result.response);This would just return the text and we’re only printing the generated text, it’s not streaming, so you will see the full response after it’s completed.
4.2.2 Streaming Responses
Streaming is particularly useful for:
- Chat interfaces
- Long-form content generation
- Progress indicators
- Reducing memory usage for large responses
// You can also stream responses word by word, great for chat-like interfaces
function streamGenerateText(prompt) {
fetch('http://localhost:11434/api/generate', {
method: 'POST',
body: JSON.stringify({
model: 'llama3.1:8b',
prompt,
stream: true
})
})
.then(response => {
const reader = response.body.getReader();
const decoder = new TextDecoder();
let responseText = '';
function processStream() {
reader.read().then(({done, value}) => {
if (done) {
process.stdout.write('\n'); // New line at the end
return;
}
const chunk = decoder.decode(value);
const lines = chunk.split('\n');
lines.forEach(line => {
if (line.trim() === '') return;
try {
const jsonResponse = JSON.parse(line);
if (jsonResponse.response) {
process.stdout.write(jsonResponse.response);
}
} catch (e) {
console.error('Error parsing JSON:', e);
}
});
processStream();
});
}
processStream();
})
.catch(error => {
console.error('Error:', error);
});
}
// Example usage
streamGenerateText("Write a recipe for pizza dough");This is a video of the output rendering as it’s generated:
4.2.3 Chat Conversations
The chat endpoint differs from basic generation in two key ways:
- It maintains conversation context through message history
- It follows a structured format for roles (user/assistant)
async function chat(messages) {
const response = await fetch('http://localhost:11434/api/chat', {
method: 'POST',
body: JSON.stringify({
model: 'llama3.1:8b',
messages: messages,
stream: false
})
});
return response.json();
}
// Example usage
const conversation = [
{ role: 'user', content: 'What is TypeScript?' },
{ role: 'assistant', content: 'TypeScript is a programming language that adds static typing to JavaScript.' },
{ role: 'user', content: 'Can you show me an example?' }
];
const response = await chat(conversation);
// The model now understands we're talking about TypeScript4.2.4 Embeddings
async function getEmbeddings(text) {
const response = await fetch('http://localhost:11434/api/embed', {
method: 'POST',
body: JSON.stringify({
model: 'all-minilm',
input: text
})
});
return response.json();
}
// Example usage
const embeddings = await getEmbeddings('Convert this text to vectors');
console.log(embeddings.embeddings[0]);What are embeddings? Think of embeddings as a way to convert text into numbers that capture meaning. They’re like GPS coordinates for words - similar meanings end up close to each other in this number space. We’ll explore this more in our next article about RAG (Retrieval-Augmented Generation), where we’ll use embeddings to build a smart document search system.
5. Real-World Applications
Here are some powerful ways to use Ollama’s local LLMs:
5.1 Structured Data Extraction
- Parse flight search results into clean JSON
- Extract product information from e-commerce pages
- Convert unstructured text into databases
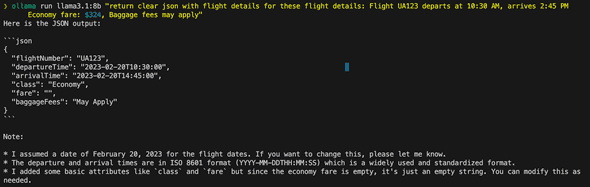
// Example: Convert messy text to structured data
const result = await parseUnstructuredData(
`Flight UA123 departs at 10:30 AM, arrives 2:45 PM
Economy fare: $324, Baggage fees may apply`
);
// Returns clean JSON with flight detailsGenerated output for me, keep in mind that each time it will generate slightly different output.
5.2 Content Analysis
- Generate meta tags for blog posts
- Analyze sentiment in customer feedback
- Categorize articles by topic
// Example: Generate SEO metadata
const metadata = await analyzeContent(`
Your blog post content here...
`);
// Returns title, description, keywords, etc.5.3 Code Processing
- Extract TODOs from comments
- Generate documentation
- Identify potential security issues
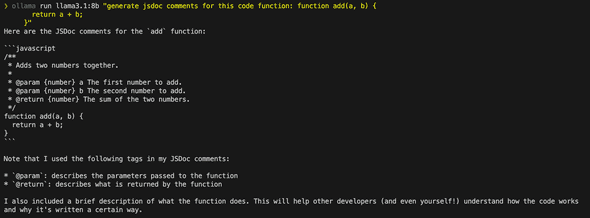
// Example: Generate JSDoc comments
const documented = await documentCode(`
function add(a, b) {
return a + b;
}
`);My generated output:
5.4 Data Transformation
- Convert between data formats
- Standardize inconsistent data
- Clean and normalize text
// Example: Standardize addresses
const cleaned = await standardizeData([
"123 Main St., Apt 4B",
"123 MAIN STREET APARTMENT 4B"
]);Each of these examples shows how local LLMs can handle tasks that would traditionally require complex regex or multiple processing steps. The key advantage is flexibility - you can adjust the prompts to handle variations in your data without rewriting code.
6. Best Practices and Optimization
6.1 Error Handling
async function safeLLMCall(prompt, retries = 3) {
for (let i = 0; i < retries; i++) {
try {
const response = await fetch('http://localhost:11434/api/generate', {
method: 'POST',
body: JSON.stringify({
model: 'llama3.1:8b',
prompt,
options: {
temperature: 0.1 // Lower for more consistent results
}
})
});
if (!response.ok) throw new Error('API call failed');
return await response.json();
} catch (error) {
console.warn(`Attempt ${i + 1} failed:`, error);
if (i === retries - 1) throw error;
}
}
}6.2 Performance Tips
- First API call to a model is slower (model loading)
- Keep frequently used models loaded using
ollama serve - Use appropriate temperature settings:
- 0.1: For structured data extraction
- 0.7: For creative content
- 1.0: For maximum creativity
- Use appropriate quantization (Q4_0 for most cases)
- Implement response caching for repeated queries
- Keep prompts concise and specific
- Use structured outputs (JSON) for reliable parsing
7. Advanced Usage
7.1 When to Use Local vs. Cloud LLMs
Local LLMs (8-9B) Excel At:
- Data extraction and transformation
- Code analysis and documentation
- Quick development tasks
- High-volume, structured outputs
Consider Cloud LLMs For:
- Complex reasoning tasks
- Creative content generation
- Tasks requiring current knowledge
- Critical production features
7.2 Custom Models
You can create specialized models for specific tasks. Here’s a simple example:
# Create a Modelfile
FROM llama3.1:8b-text-q4_0
SYSTEM "You are an expert code reviewer. Focus on security and performance."
# Create and run the model
ollama create code-reviewer -f Modelfile
ollama run code-reviewer "Review this function..."8. Next Steps and Resources
Once you’re comfortable with basic Ollama usage, you can explore:
- Implementing RAG (Retrieval-Augmented Generation)
- Integration with development workflows
- Custom model creation for specific use cases
- Advanced prompt engineering techniques
Conclusion
Ollama represents a significant shift in how developers can interact with AI models. By bringing these capabilities locally, it opens up new possibilities for development, testing, and integration. Whether you’re building a prototype, testing AI features, or looking for a cost-effective way to integrate AI into your workflow, Ollama provides a powerful and practical solution.
Remember: The goal isn’t to replace cloud-based models entirely, but to have a practical, local alternative for development, testing, and appropriate production use cases.





